
DISCLAIMER: As much as we love AI and LLMs, one thing we can’t stand are cookie cutter blogs where you can immediately determine they were created entirely with AI. So, while you will see tons of awesome AI examples and content on this website in other blog posts, you’ll NEVER see AI generated content within our model reviews. These will always be entirely human written, always.
So, what is a model? It’s a file that contains a bunch of numbers. These numbers, typically tensors, are used matrix weights, or variable coefficients. From a higher level, they’re numerical inputs that help operate a big function that we call a network. AI is peculiar in the fact that words overlap quite a bit. So be prepared to encounter that relatively often.
ssd-mobilenet-v2

We do a ton of Nvidia Jetson Edge AI programming. This requires us to use really small efficient models, especially with respect to computer vision. How can we get the best bang for our buck? If we want to do object detection and the pre-trained basic (person, car, etc.) classes are enough, then ssd-mobilenet-v2 should fit the bill. SSD (single shot multi-box detection), meaning it can detect multiple objects with a single pass-thru of the network. This makes the model much more efficient, and quicker, for you to retrieve value from.
Pytorch Implementation: https://github.com/qfgaohao/pytorch-ssd
Jetson-Inference Implementation: https://github.com/dusty-nv/jetson-inference/blob/master/docs/detectnet-example-2.md
from jetson_inference import detectNet
from jetson_utils import videoSource, videoOutput
net = detectNet("ssd-mobilenet-v2", threshold=0.5)
camera = videoSource("/dev/video0") # '/dev/video0' for V4L2
display = videoOutput("display://0") # 'my_video.mp4' for file
while display.IsStreaming():
img = camera.Capture()
if img is None: # capture timeout
continue
detections = net.Detect(img)
display.Render(img)
display.SetStatus("Object Detection | Network {:.0f} FPS".format(net.GetNetworkFPS()))This particular bit of code can only be run on a Nvidia Jetson device after you have cloned, compiled, and installed jetson-inference or are on a device within a jetson-inference docker container.
CLIP
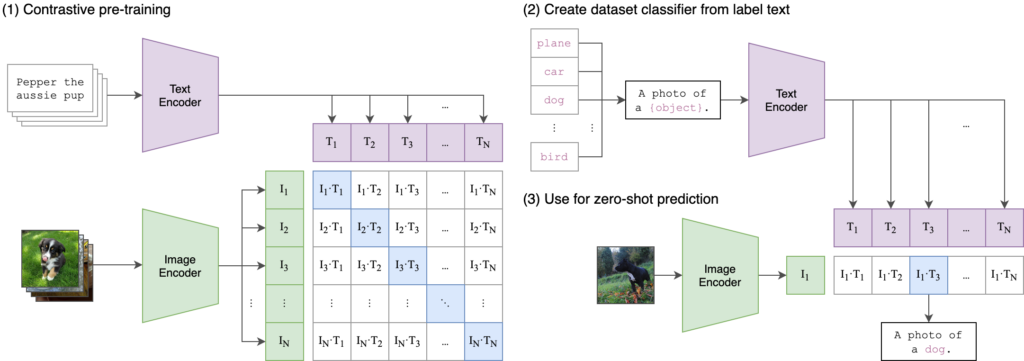
CLIP (Contrastive Language-Image Pre-Training) by OpenAI immediately accelerated the entire AI industry. CLIP allows us a quick way to caption images, or do image classification, without having to pretrain on specific classes. Why is this so frickin sweet? Because say for example you have a huge database full of unlabeled images, and you want to make that database of images searchable. But not searchable in the traditional sense where you are tagging image and text pairs in the backend, and then using text search queries to retrieve the images. Instead, CLIP allows us to use an image as the search query itself! Our own personal reverse image search!! Of course, you’re not limited to just using the image as the search query, since the embeddings also contain textual information, you can also search via class. How is that not frickin sweet?
Not to mention the limitless possibilities of this providing a really excellent layer within future multi-modal model networks.
tldr; the whitepaper on this one is good!
I don’t recommend typically wasting away hours of your day reading whitepapers either. But CLIP is a foundational multi-modal paper that I think is educating enough that it certainly provides values a multi-modal introduction as well.
OpenAI CLIP Home: https://openai.com/index/clip/
Whitepaper: https://arxiv.org/abs/2103.00020
Code: https://github.com/openai/CLIP
Huggingface.co Implementation (easiest/quickest implementation): https://huggingface.co/docs/transformers/model_doc/clip
Best Online DEMO (IMO): https://huggingface.co/spaces/radames/OpenAI-CLIP-JavaScript
Paligemma
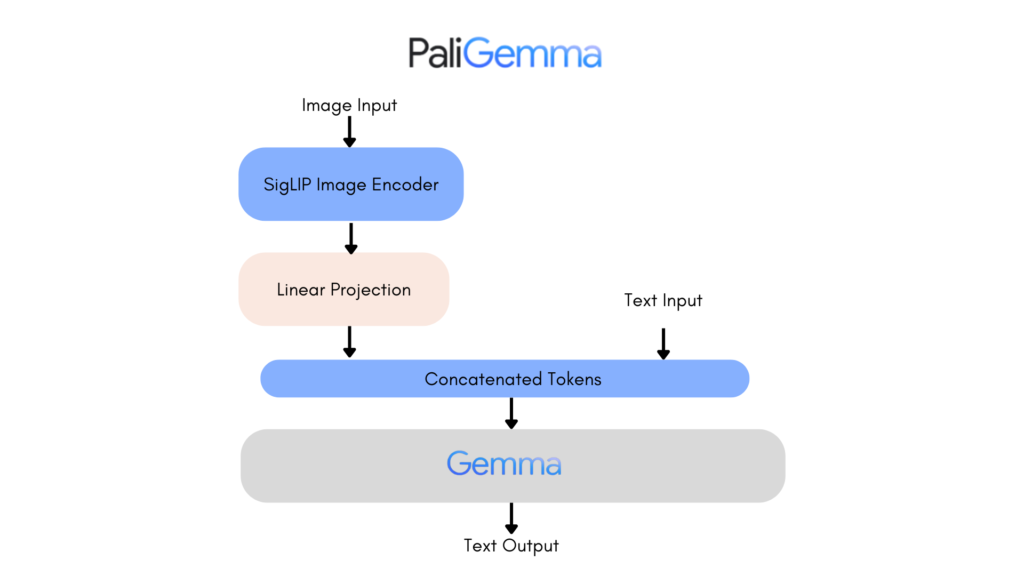
Paligemma is a relatively new multi-modal model that reminds me a bit like CLIP, but not exactly. Where CLIP is a hammer, I feel like Paligemma is a surgeon. But this is just my feeling, in reality CLIP and Paligemma couldn’t be more different (especially via their architecture).
Where Paligemma really shines to me is visual question/answering, coupled with Google’s already proven ability to really exceed expectations with OCR (Optical Character Recognition) and Document understanding. BUT. THAT. IS. NOT. ALL. Visual QA gives us light classification, but also pretty good object detection and segmentation! I mean, you really gotta love multi-modal models.
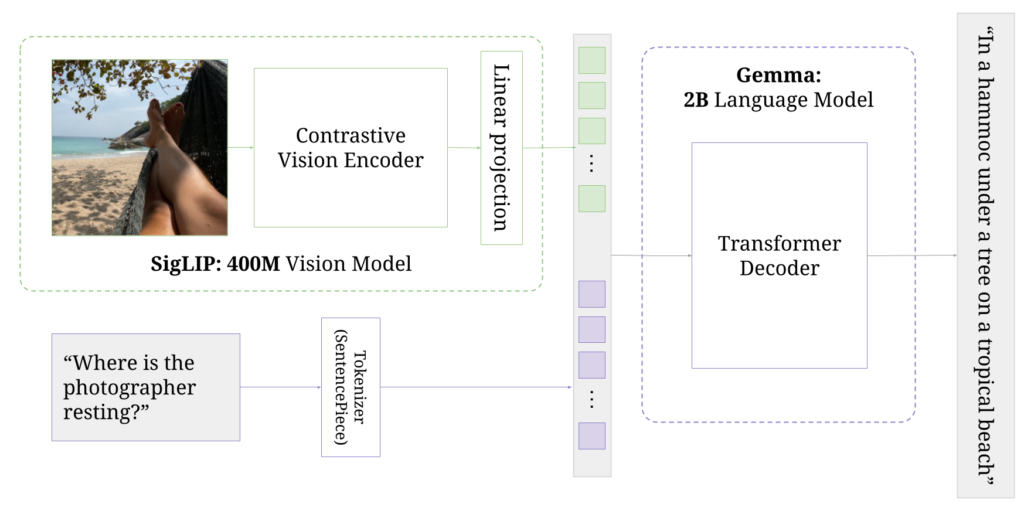
Paligemma also integrates really nicely into personal, or narrow use-case scenarios with it’s simple transfer learning abilities. Meaning adding your own classes for object detection, and classification, etc, are all pretty straight forward and simple.
We see a long lifespan for Paligemma here at enfuse.ai, this won’t be the last time we encounter it.
Paligemma Post on HF: https://huggingface.co/blog/paligemma
Paligemma Github: https://github.com/google-research/big_vision/blob/main/big_vision/configs/proj/paligemma/README.md
Huggingface.co Implementation (Quickest / easiest): https://huggingface.co/blog/paligemma#using-transformers
Enfuse.ai Model Spotlight Demo: https://enfuse.ai